
링고선생님의 파이썬 데이터분석 프로젝트 강의!
강의자료로는 3-8.combine 내용이고, 오늘은 여러 개의 표를 가로/세로로 합치는 방법을 정리하려고 한다.
강의는 홈페이지에서 구매할 수 있음..!(사진 누르면 링크 이동)
🔥 강의 목차
오리엔테이션
파이썬 기초 문법
데이터 전처리
데이터 시각화
마케팅 데이터 분석 및 지표 정의하기
🔥 세로로 합치기 concat()
일단, 데이터를 세로로 합치고 싶을 때가 있다. 세로로 합친다는 것은 열은 똑같이 유지하되, 케이스(=데이터=행)가 늘어난다는 의미이다. python에서는 판다스 라이브러리에서 pd.concat()을 사용해 데이터를 합칠 수 있다. 엑셀에도 concat() 함수가 있지만 기능이 약간 다르다. SQL에서는 UNION과 같은 기능이라 생각하면 된다.
일단은, 예시 데이터를 만들고
import pandas as pd
# 세 개의 예시 데이터프레임 생성
df1 = pd.DataFrame({'Name': ['Alice', 'Bob'], 'Age': [25, 30]})
df2 = pd.DataFrame({'Name': ['Chris', 'David'], 'Age': [22, 27]})
df3 = pd.DataFrame({'Name': ['Eve', 'Frank'], 'Age': [28, 33]})


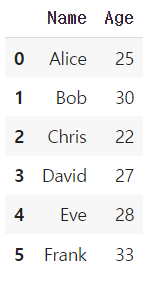
세 표를 합쳐서 2열, 6행의 데이터가 되도록 결합하려고 한다. concat() 안에 리스트 형태로 결합할 데이터프레임을 적고, ignore_index = True를 입력한다.
result = pd.concat([df1, df2, df3]
, ignore_index=True
)
result
그러면, 아래와 같은 결과물을 얻을 수 있다. ignore_index = True 옵션을 사용하는 이유는, 결합 이전에 df1 테이블에서는 앨리스와 밥의 index가 0, 1이었고, df2 테이블에서는 크리스와 데이비드의 index가 0, 1이었고, df3에서는 이브와 프랭크의 index가 0, 1이었으므로 각 데이터프레임 내의 인덱스를 무시하고, 합쳐진 후 새롭게 인덱스를 설정하겠다는 의미이다.
ignore_index = False로 사용할 일은 특수한 일을 제외하고는, 거의 없다.
🔥 가로로 합치기 join()
데이터를 가로로 합쳐야 하는 경우도 있다. 가로로 합친다는 것은 해당 데이터에 대한 정보가 다양해짐을 의미한다. 예를 들어, 이름+생년월일 정보가 있는 테이블과 이름+거주지역 테이블을 합치면 이름+생년월일+거주지역이 되는 식이다. SQL의 JOIN과 거의 유사하다.
1) JOIN의 기본 형태
merged = pd.merge(left_df, right_df
,left_on = 'left_key' , right_on = 'right_key'
, how='join_type'
)
# key_l과 key_r을 하나의 열로 통합
merged['new_key'] = merged['key_l'].combine_first(merged['key_r'])
# join_type -> inner, outer, left, right, cross('on' argument 필요없음)
2) JOIN의 종류


- INNER JOIN: 공통된 key에 대해서만 결합 (and 조건)
- OUTER JOIN: 모든 key를 포함하며, 일치하지 않는 경우 NaN으로 채움 (or 조건)
- LEFT JOIN: Left 테이블의 key를 기준으로 결합, 일치하지 않는 경우 NaN으로 채움
- RIGHT JOIN: Right 테이블의 key를 기준으로 결합, 일치하지 않는 경우 NaN으로 채움
- CROSS JOIN: 테이블 간의 모든 조합을 생성
이론적으로는 위와 같이 표현할 수 있지만, 직접 데이터로 실습해 보면서 형태를 익히는 것이 가장 이해하기 쉽다.
예시 데이터를 생성한 뒤 직접 테스트 해보자.
예시 데이터는 아래와 같다. left, right 두 개의 표를 출력하면 아래와 같다.
import pandas as pd
# 예시 데이터프레임 생성
left = pd.DataFrame({
'key_l': ['K0', 'K1', 'K2'],
'col_1': [ 'A1', 'A2', 'A3'],
'col_2': [ 'B1', 'B2', 'B3']
})
right = pd.DataFrame({
'key_r': [ 'K1', 'K2', 'K3'],
'col_1': ['C0', 'C1', 'C2'],
'col_2': ['D0', 'D1', 'D2']
})

2-1) INNER JOIN
먼저 INNER JOIN은 두 표에서 일치하는 KEY만 가져온다고 했다. 그게 무슨 소리냐, 예시로 봤을 때 left 테이블의 key_l 컬럼에는 K0, K1, K2 세 개의 key가 있고, right 테이블의 key_r 컬럼에도 K1, K2, K3 세 개의 key가 있다.
일치하는 key는 K1, K2 두 개이므로, 총 2개의 행만 가지고 와서 두 테이블을 가로로 결합한다. 아래 결과에서 일치하는 key(K1, K2)에 해당하는 부분이 가로로 합쳐진 것을 확인할 수 있다.
merged = pd.merge(left, right
, left_on = 'key_l', right_on = 'key_r'
, how='inner')
merged
2-2) OUTER JOIN
OUTER JOIN은 모든 key를 가져오고, 어느 한 쪽에 데이터가 없으면 그 부분은 NaN으로 채운다. left 테이블의 K0, K1, K2와 right 테이블의 K1, K2, K3를 겹치지 않게 세면 K0, K1, K2, K3 총 4개의 key값이 나온다. 따라서 OUTER JOIN을 하면 4개의 행으로 이루어진 테이블이 나온다.
right 테이블에 값이 없는 K0, left 테이블에 값이 없는 K3 행이 NaN으로 표시된 것에 주목하자.
merged = pd.merge(left, right
, left_on = 'key_l', right_on = 'key_r'
, how='outer')
merged
2-3) LEFT JOIN
LEFT JOIN은 좌측 테이블의 key를 모두 가져오고, 우측 테이블에만 있는 값은 버린다. left 테이블에 K0, K1, K2가 있고, right 테이블에 K1, K2, K3이 있으므로 left에 해당하는 3개의 key를 불러와서 right 테이블을 가로로 합친 다음, right 테이블에만 있는 K3 데이터는 버린다.
merged = pd.merge(left, right
, left_on = 'key_l', right_on = 'key_r'
, how='left')
merged
2-4) RIGHT JOIN
RIGHT JOIN은 LEFT JOIN과 반대로, 우측 테이블의 key값을 기준으로 모두 가져온 다음, 좌측에만 있는 행을 버린다. 아래 표를 보면 K1, K2, K3가 모두 있지만 left 테이블에만 있던 K0 행은 사라진 것을 볼 수 있다.
merged = pd.merge(left, right
, left_on = 'key_l', right_on = 'key_r'
, how='right')
merged
2-5) CROSS JOIN
CROSS JOIN은 가능한 모든 경우의 수를 조합하여 결과를 출력한다. 곱하기라고 생각하면 쉬운데, 좌측 테이블의 모든 행 * 우측 테이블의 모든 행을 곱해 가능한 모든 조합을 계산하여 출력한다. K0, K1, K2와 K1, K2, K3 로 만들 수 있는 조합은
K0-K1 / K0-K2 / K0-K3 / K1-K1 / K1-K2 / K1-K3 / K2-K1 / K2-K2 / K2-K3 총 9개(3 x 3)일 것이다. 그러므로 결과도 9개의 행이 출력된 것을 볼 수 있다.
merged = pd.merge(left, right
, how='cross')
merged
이래저래 필요한 데이터 형태에 따라 join 또는 combine()을 이용해 원하는 테이블로 만들 수 있어야 한다! 🔥
* 본 게시글은 '메타코드'의 동의를 받아 작성된 글로, 강의 내용에 대한 모든 저작권은 Ringo 선생님에게 있습니다. 개인용도의 학습 외에 무단사용은 엄격히 금지됩니다. 위반 시 법적 조취가 취해질 수 있습니다.
'빅데이터분석' 카테고리의 다른 글
| [파이썬] 파이썬 입문 데이터분석 프로젝트 만들기 - (15) 데이터타입 확인/변경 .astype(), to_numeric() (0) | 2024.05.29 |
|---|---|
| [파이썬] 파이썬 입문 데이터분석 프로젝트 만들기 - (14) 피벗테이블 pivot (0) | 2024.05.26 |
| [파이썬] 파이썬 입문 데이터분석 프로젝트 만들기 - (12) groupby 그룹별 집계하기 (1) | 2024.05.19 |
| [파이썬] 파이썬 입문 데이터분석 프로젝트 만들기 - (11) Dates & Times 날짜/시간 데이터 다루기 (0) | 2024.05.19 |
| [파이썬] 파이썬 입문 데이터분석 프로젝트 만들기 - (10) 조건에 맞는 데이터 필터링(filtering) (0) | 2024.05.12 |



