
메타코드에 새로 올라온 powerBI 강의! (이미지를 클릭하면 수강신청 링크로 이동한다.) 10월 3일까지 완전 무료로 들을 수 있다.
이번 글에서는 지난 글에 이어 EDA 뒷부분을 정리할 예정이다.
2. EDA-시각화
이 강의에서는 count plot과 histogram을 그려본다.
histogram은 수치형 변수들, count plot은 범주형 변수들을 대상으로 시각화할 때 사용한다.
px 로 그래프를 그리면 되는데, 어떻게 그리는지 잘 모르겠다면.. help와 dir을 사용하자.
빅분기 실기할 때도 help와 dir을 엄청 많이 썼는데, px라는 라이브러리에 어떤 그래프들이 있는지 궁금할 때는 dir, 사용법이 궁금할 때는 help(px.histogram)처럼 사용한다.
# dir(px)
# help(px.histogram)
1) Histogram
dir과 help를 적절히 사용해 어떤 상수가 들어갈지 알아냈다면, 가장 간단한 나이 히스토그램을 그려보자.
최저 16세부터 최장 80대까지 있는 그래프를 볼 수 있다.

2) Count_Plot
범주형 변수의 경우 count_plot을 그릴 수 있다. 범주형 변수 같은 건 빈도가 가장 많은 것 순으로 나열하면 좋은데, 가장 기본 형태로 그렸을 때에는 빈도순으로 나열되지 않는다.

이럴 때는 category_orders 옵션을 추가해서 순서를 맞춰줄 수 있다.
df['MaritalStatus'].value_counts().index() 라는 코드만 실행하면 MaritalStatus 컬럼의 범주마다 개수를 세고, 개수가 가장 많은 것부터 내림차순으로 나열한 뒤, 그 결과의 index에 해당하는 컬럼명만 불러오게 된다.
이 내용을 category_orders에 넣어서 순서를 내림차순으로 맞춰줄 수 있다.
# 카테고리 순서(category_orders 지정)
px.histogram(df, x='MaritalStatus', title = 'Count plot of MaritalStatus',
category_orders={'MaritalStatus':df['MaritalStatus'].value_counts().index})
여기까지 간단한 EDA와 시각화를 해보았다.
데이터가 한 눈에 보이고 좋긴 한데, 매번 모든 컬럼, 혹은 데이터에 대해 동일한 코드를 치고 있는 건 비효율적이다.
함수 형태로 만들어서 재사용 가능하도록 만들어 시간/비용을 절약해보자.
3) Count Plot 함수로 만들기
def count_plot(df, column):
fig = px.histogram(df, x=column, title=f"Count plot of {column}",
category_orders={column:df[column].value_counts().index})
fig.show()
return fig
(1) def count_plot()
def로 함수명을 정의하고, 받을 값을 지정한다.
(2) 매개변수(파라미터) 지정
여기에서는 데이터프레임(df)을 받아오고, 알고 싶은 컬럼의 이름(column)을 함께 받아와서 그래프로 그린다.
(3) f-string을 활용하여 받는 컬럼에 따라 그래프 제목이 변하도록 설정한다.
f"Count Plot of {column}"으로 설정하면 column 매개변수로 받은 이름을 그대로 받아서 그래프명 적는다.
(4) fig 라는 변수에 그래프를 저장하고, fig.show()로 표시되게 해준다. 반환값도 fig로 한다.
정의한 함수명과 원하는 파라미터를 넣으면 함수가 실행되고, 바로 그래프가 그려지는 걸 확인할 수 있다.

4) Histogram 함수로 만들기
count plot에서 category_orders만 제외하면 쉽게 함수화 할 수 있다.
def histogram_plot(df, column):
fig = px.histogram(df, x=column, title=f"Histogram plot of {column}")
fig.show()
return fig
5) 수치형/범주형 변수 한 번에 파악
일단 모든 컬럼의 값을 가져와서 그래프를 그리는 것이기 때문에, 루프(loop)를 사용해야 한다.
pd.api.types.is_numeric_dtype()을 사용하면 수치형 변수인지(True), 범주형 변수인지(False) 판단할 수 있다.
pd.api.types.is_numeric_dtype()
for문 내에 if~ else 구문을 사용해서, numeric인지, object인지 판단하는 코드를 짜면 뭐가 수치형이고 뭐가 범주형인지 한 번에 알 수 있다.
for column in df.columns:
print(column)
if pd.api.types.is_numeric_dtype(df[column]):
print("Numeric")
elif pd.api.types.is_object_dtype(df[column]):
print("Object")
(6) 그래프 한 번에 그리기
앞서 만들었던 histogram_plot()함수와 count_plot() 함수를 넣어준다.
fig_list = list()와 fig_list.append(fig)는 모든 그래프들을 리스트로 저장하기 위해 추가한 코드이다.
plot_df라는 함수에 전체 코드를 넣어서 저장 가능!
def plot_df(df):
fig_list = list()
for column in df.columns:
if pd.api.types.is_numeric_dtype(df[column]):
fig = histogram_plot(df, column)
elif pd.api.types.is_object_dtype(df[column]):
fig = count_plot(df, column)
fig_list.append(fig)
return fig_list
이제, 데이터프레임(df)만 집어넣어도 각 컬럼이 수치형 변수인지 범주형 변수인지 판단하고, 그에 맞게 히스토그램 또는 카운트 플롯을 그려주는 함수가 완성되었다.
plot_df(df) 으로 데이터프레임을 넣으면 모든 컬럼에 대해 그래프가 그려진다.
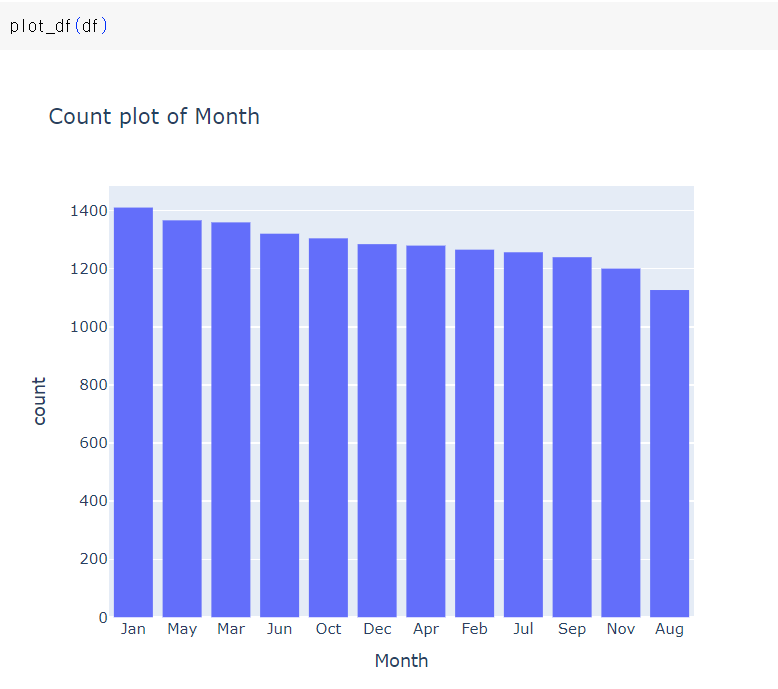

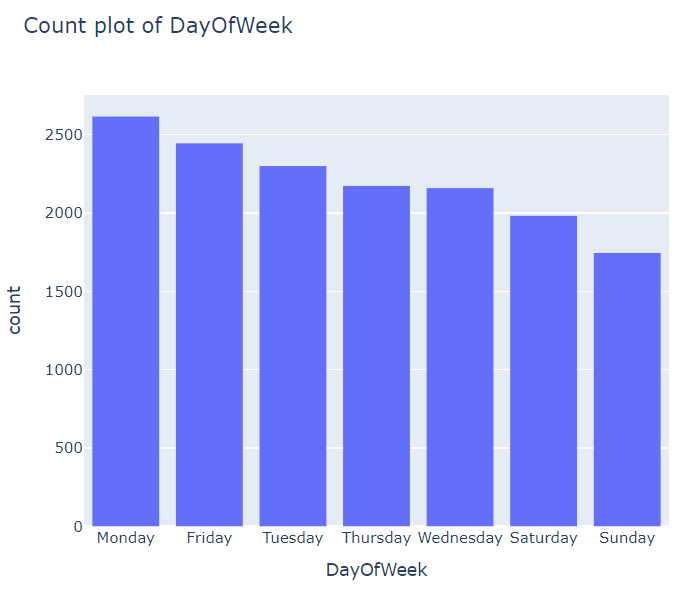
33개 그래프는 너무 많아서 이하 생략..
남자가 많다 / 피보험자 본인이 사고를 많이 낸다 / 세단 종류 사고가 가장 많다 / 보험사기여부 등등
함수를 만든 다음에는 파이썬 파일을 하나 만들어서 함수를 넣어두는 게 좋다.
강사님 같은 경우에는 utils.py 라는 파일에 전부 넣어 두었기 때문에 추후에 컴퓨터에서 import 해서 읽어올 수 있다.
from utils import plot_count_plot, plot_histogram, plot_dataframe
# plot_count_plot(df, 'Make')
plot_dataframe(df)
만약 utils라는 py 파일에 위 함수를 저장했다면 import를 통해 불러와서 사용해보자! 똑같은 결과가 나온다.
함수를 만든 다음에는 함수에 대한 설명을 달아두는 것이 좋다.

정리하자면,
def 함수명(파라미터):
""" 이 사이에 설명 넣은 다음 """
함수에서 실행할 코드들
return 리턴값
이렇게 utils.py 파일에 저장을 해두면 언제든 from utils import 함수명 을 통해 불러올 수 있다.
다음엔 보험 관련 도메인 지식을 알려준다고 하셨다. 😄 나중에 보험 들거나 보험금 받을 때도 유용하지 않을까? 싶어서 기대 중...!
* 메타코드 서포터즈로서 강의를 제공받아 작성하였습니다. 이미지를 클릭하면 홈페이지로 이동합니다.
'빅데이터분석' 카테고리의 다른 글
| [powerBI] 메타코드 강의후기_(3) 기초통계 개념 (2) | 2024.10.06 |
|---|---|
| 구글코랩(Colab)에서 py파일 저장하고 불러오기! (2) | 2024.10.03 |
| [powerBI] 메타코드 강의후기_(1) EDA 자동화 (4) | 2024.09.29 |
| [메타코드] 파이썬 입문 데이터분석 - 마케팅 데이터분석 및 지표정의 (2) Conversion Window 2 (0) | 2024.07.31 |
| [메타코드] 파이썬 입문 데이터분석 - 마케팅 데이터분석 및 지표정의 (2) Conversion Window (0) | 2024.07.31 |


