
🔥 메타코드에서 머신러닝 입문 부트캠프 강의를 듣기 시작했다.
사회조사분석사 자격증을 취득하고, ADsP, SQLD, 빅분기까지 거쳐 오면서 다양한 강의들을 접하고 공부했다.
근데 머신러닝이 뭔지 아직도 제대로 모르는 것 같다.
어렴풋이 느끼는 건 머신러닝 => 빅분기 2유형에서 푸는 것? RandomForest 같은 모델 import 해서 돌리는 것...? 인데, 빅분기를 취득했음에도 부끄럽게 하이퍼파라미터 최적화/튜닝 같은 건 모른다.
그도 그럴 것이, 빅분기는 하이퍼파라미터에 손대지 않고 기본만 딱 하는 게 가장 점수가 높게 나온다는 썰이 많았기 때문이다. 실제로 나도 그런 경험을 했고...ㅠ
그래서 이번에 또 서포터즈로 혜택을 받게 된 김에 머신러닝 입문 부트캠프 강의권을 지원받아서 듣게 되었다.
이 강의를 들으면 이제 하이퍼파라미터 튜닝이 왜 필요하고 어떤 의미를 가지는지 알 수 있으리라 기대 중....!
(애석하게도 직전까지 듣고 있던 powerBI 강의는 무료 기간이 끝나서 더이상 못 듣는다....! ㅠ 잘 듣고 있었는데 아쉽다.)
강의를 들어보니, 이론부터 꼼꼼하게 짚어주시는 게 맘에 든다. 그럼, 모닥불🔥의 메타코드 강의 후기 시작!!
1. 머신러닝이란?

인공지능 > 머신러닝 > 딥러닝 순으로 포함관계라는 건 이미 많이 들어서 알고 있었다. 머신러닝은 통계적 기법/경사하강법으로 최적의 파라미터를 찾아나가는 과정이라면, 딥러닝은 인공신경망 개념이 도입된 것을 말한다. 그리고 딥러닝은 데이터의 양 자체가 100만 이상, 천만 ~ 억 단위를 넘을 만큼 많다는 것이 또다른 특징이다.

머신러닝이라는 것은, 말 그대로 기계 학습인데, 나는 기계가 학습한다고 생각했는데 기계를 학습한다는 뜻이었다. 뭐 큰 차이는 없지만... 머신러닝의 머신은 우리가 생각하는 끼긱 끼긱 기계라기 보다는, 인간이 제공한 데이터를 표현할 수 있는 모델을 말한다. 모델은 쉽게 말하면 함수라고도 표현할 수 있다고 한다.
머신러닝에서 학습이라는 것은, 주어진 데이터를 가장 잘 표현할 수 있는 모델(=함수)을 찾는 것이다. 이를 위해 통계적 기법이나 경사하강법 등을 사용해 최적의 파라미터를 찾는다.
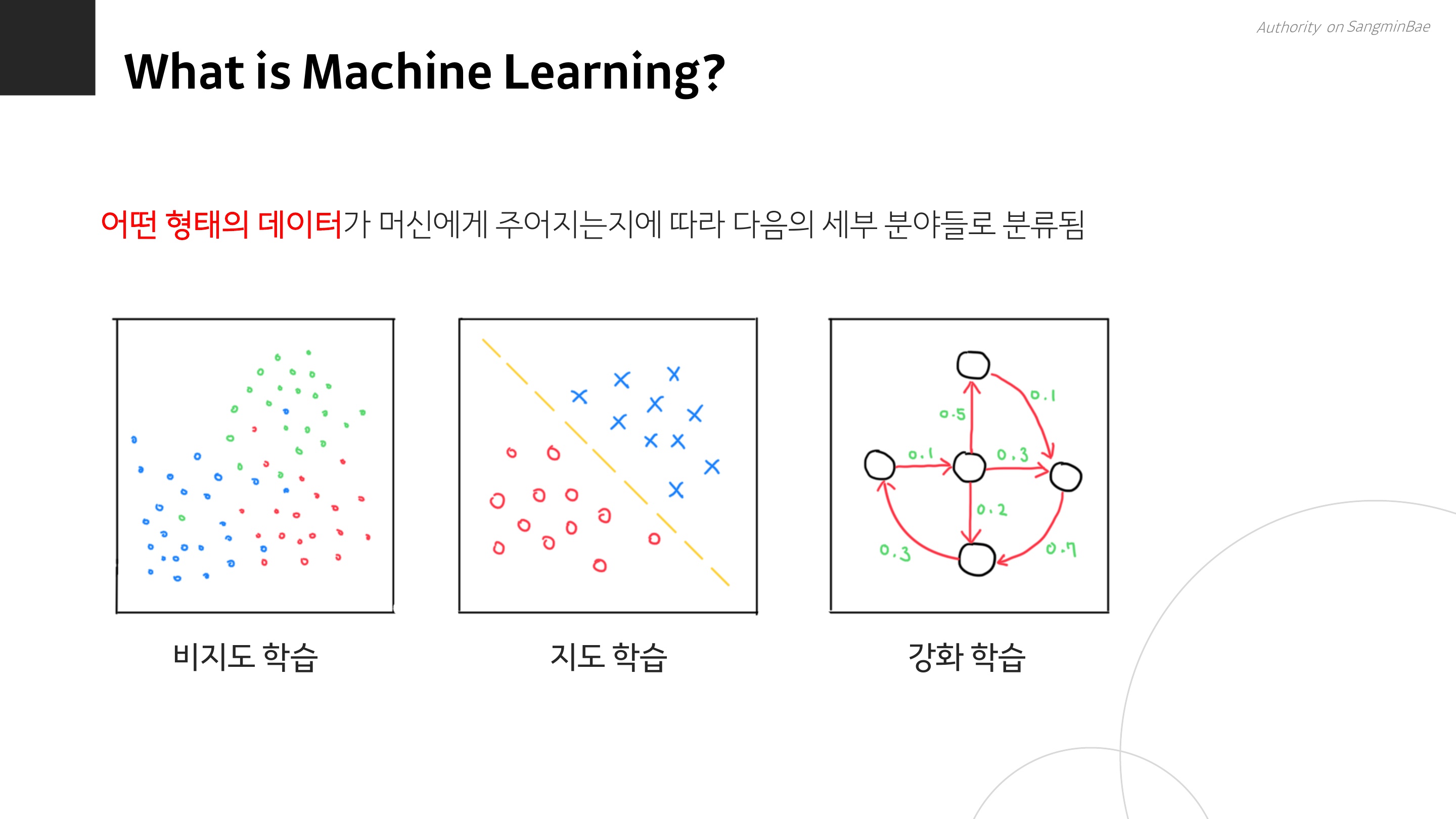
머신러닝은 비지도학습, 지도학습, 강화학습으로 나눌 수 있다. 이 강의에서는 지도학습과 비지도학습 위주로 다루고, 강화학습은 그다지 다루지 않는다고 한다. 알파고, 챗GPT 같은 인공지능에 강화학습이 사용되었다고 한다. 나는 나름, 심리학과 출신으로서 강화 학습에 대해 배웠는데 보상을 주는 행동은 강화되고 보상이 없거나 처벌을 받는 행동은 점차 쇠퇴한다는 것이 강화 학습의 기본 개념이다. 그 개념을 인공지능에 적용시키면 위 그림 같은 형태가 되는....
지도 학습과 비지도 학습은 빅분기 공부했던 사람이라면 달달 외웠겠지만, x, y를 쌍으로 주고 학습시키면 지도학습이고, 특징을 가진 데이터를 주고 알아서 학습하게 두면 비지도 학습이다.
2. 회귀(Regression) - 용어(Notation)

지도학습은 다시, 회귀(Regression)와 분류(Classification)로 나뉜다.
회귀와 분류 모두 입력값은 어떤 형태이든 상관 없으나, 회귀는 출력값이 연속값(실수형)이고, 분류는 출력값이 이산형(범주형)이다. 회귀 모델의 형태는 y = ax + b 같은 일반 함수 형태인데, 기울기(a)와 절편(b)을 가중치(w1, w0)로 표기했을 뿐..! 우리가 알고 있는 1차 함수, 2차 함수 등과 동일하다.
분류 모델은 2개의 범주로 나뉘는 이진분류와 3개 이상의 범주로 나뉘는 다중분류로 다시 나눌 수 있는데, 이진 분류일 때는 기존 모델(y = w1x + w0)에 시그모이드 함수를, 다중분류일 때는 소프트맥스 함수를 포함한다.

데이터는 피처와 라벨로 구성된다. 피처(feature)는 독립변수라고도 불리고, x로 표시한다. 라벨(label)은 모델이 예측하고 싶은 변수로, 종속변수라고도 불리며, y로 표기한다.
라벨(y) 여부와 형태로 지도학습(분류/회귀)과 비지도학습을 나눈다. 굳이 표로 나타내자면 아래와 같은...?
| 라벨(y) 있음 | 라벨(y) 없음 | |
| 라벨이 수치형 변수 | 지도학습 - 분류 | 비지도학습 |
| 라벨이 범주형 변수 | 지도학습 - 회귀 |

파라미터와 하이퍼파라미터 개념이 나온다.
아까 최적의 파라미터를 찾는다고 했었는데, 파라미터는 y = ax + b 에서 a, b 같은 부분을 말한다. 우리가 y = 2x+3 이라는 함수에 x = 2라는 숫자를 넣으면 y가 7로 나오는 것처럼, 입력한 데이터 값(x) 외에 모델(함수)이 가지고 있는 학습 가능한 부분을 파라미터라 한다. 다른 말로는 가중치(w)라고도 불린다. 그래서 y = w1x + w0 이렇게도 표현함!
하이퍼파라미터는 전문가가 직접 정해주어야 하는 변수로, 학습률이나 배치 크기 등이 있다.
머신러닝, 인공지능 모델은 아직 완벽하지 않기 때문에,
1. 데이터가 주어져야 한다.
2. 모델에 대한 정의가 필요하다.
3. 하이퍼파라미터 정의가 필요하다.
현재는 딥러닝에서 하이퍼파라미터를 별도로 설정하지 않는 autoML 분야가 연구되고 있다고 함.

입력값(input)과 출력값(output)은, 다들 아는 내용으로 x, 피처(feture), 독립변수가 input이 되고, 이를 바탕으로 출력된 예측값 y햇(y^)을 output이라고 한다.
y햇은 모델에서 출력된 예측값으로, 실제 y와는 다르다. y와 y햇의 차이를 손실값, 또는 오류라고 한다.
여기까지는 다 아는 내용인데,... 이제부터 조금씩 정의가 어려워진다. ㅠ-ㅜ 심호흡 하고 다음 글에서 정리하겠음...
그럼 이만, 화르륵🔥🔥

* 메타코드 서포터즈로서 강의를 제공받아 작성하였습니다. 이미지를 클릭하면 홈페이지로 이동합니다.
'빅데이터분석' 카테고리의 다른 글
| [머신러닝] 메타코드 강의 후기_머신러닝 입문 부트캠프 (3) 선형 회귀(Linear Regression)와 최적화(optimization) (1) | 2024.10.20 |
|---|---|
| [머신러닝] 메타코드 강의 후기_머신러닝 입문 부트캠프 (2) 머신러닝에 사용되는 기본 수학 개념 (2) | 2024.10.13 |
| [powerBI] 메타코드 강의후기_(4) 가설설정 및 통계적 검정 (2) | 2024.10.06 |
| [powerBI] 메타코드 강의후기_(3) 기초통계 개념 (2) | 2024.10.06 |
| 구글코랩(Colab)에서 py파일 저장하고 불러오기! (2) | 2024.10.03 |



